Any debt/loan comes at a cost (interest rate), so home-loan is not an exception.
As per Indian Taxation, one can save;
up to Rs. 2,00,000 under Section 24(b) on the interest portion
And, up to Rs. 1,50,000 can be claimed under Section 80C for the principal repayment.
Conditionally, additional Rs.50,000 under Section 80EE or Rs. 1,50,000 can be claimed under 80EEA
EMI has 2 components:
Interest payment
Principal repayment
The more you payoff at start more the benefits. ( Please check with your bank before depositing extra small amount, some banks allow only few attempts to repay before due date )
A person in 30% tax slab decides to keep the loan for longer then, that person can save maximum Rs. 75,000 per year but, pays huge interest to the bank.
Therefore, as per the calculations; its always better to payoff your loan as early as possible than waiting for minor income tax gains.
– There are typically two types of graph system vendors:
OLTP graph databases
OLAP graph processors
JanusGraph: A Graph DB
It is designed to support the processing of graphs so large that they require storage and computational capacities beyond what a single machine can provide. Scaling graph data processing for real-time traversals and analytical queries is JanusGraph’s foundational benefit.
Benefits of JanusGraph:
It promises support for a wide variety of open source
Use CAP theorem to decide DB, one has to choose between Consistency (HBase) & Availability (Cassandra)
analytics engines (Spark’s GraphX, Flink’s Gelly)
and search engines (ElasticSearch, Solr)
– Scales really well the number of machines & very performant with concurrent transactions and operational graph processing.
– Support for geo, numeric range, and full-text search for vertices and edges on very large graphs.
– Native support for the popular property graph data model exposed by Apache TinkerPop.
TinkerPop provides an abstraction over different graph databases and graph processors allowing the same code to be used with different configurable back-ends.
– Native support for the graph traversal language Gremlin.
Gremlin is a functional, data-flow language that enables users to succinctly express complex traversals on (or queries of) their application’s property graph.
Gremlin was designed according to the “write once, run anywhere”-philosophy.
The benefit is that the user does not need to learn both a database query language and a domain-specific BigData analytics language (e.g. Spark DSL, MapReduce, etc.). Gremlin is all that is required to build a graph-based application because the Gremlin traversal machine will handle the rest.
– Vertex-centric indices provide vertex-level querying to alleviate issues with the infamous supernode problem.
– Open source under the liberal Apache 2 license.
What should people know when deciding between Neo4j and JanusGraph?
– Neo4j Community Edition uses the GNU General Public License, which has more restrictive requirements on distributing software. Many developers eventually need the scaling and availability features that are only available in the Neo4j Enterprise Edition, which requires a commercial subscription license.
– Neo4j is mostly a project that is kind of self-contained. What I mean by this is that it implements its own storage engine, indices, a server component, network protocol, and query language.
– Neo4j mostly promotes their own query language—Cipher
– TinkerPop is compatible with many other vendors, including Amazon Neptune, Microsoft Azure Cosmos DB, and DataStax Enterprise Graph, although keep in mind that many of the TinkerPop implementations are not free to open source.
(when cache is enabled; cache.db-cache = true ) If any Janusgraph server is running & you run a new Janusgraph server to modify the schema, it fails due to “locked” keyspace.
Cannot instantiate server, it connects to already running server.
Support only Java
Clients from a variety of languages can access Janusgraph.
JanusGraph & Application are tightly bound, that’s the reason this approach is called “embedded”
You can scale JanusGraph, backend, and application independently of one another.
Perform Get-or-Create Traversal in a single step, so that it just reduces the race condition time window with the omitted additional network round-trip between application and the JanusGraph Server.
JanusGraph instance caching should be disabled.
Schema having not only unique constraints on properties but also multiplicities other than MULTI on edge labels.
Get-or-Create Traversal example:
// This import is necessary to resolve unfold, addV methods
import static org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.__.*
g.V().has("code","XYZ").fold().coalesce(unfold(),addV().property("code","XYZ"))
Notes:
Property keys used on edges and properties have cardinality SINGLE. Attaching multiple values for a single key on an edge or property is not supported.
Cassandra Thrift protocol is deprecated and will be removed with JanusGraph 0.5.0. Please switch to the CQL backend.
When a vertex is deleted its incident edges are also deleted.
drop().iterate() succeeds even if Vertex/Edge does not exists
Is it preferable to use bytecode or gremlin script?
Bytecode is the recommended way and Gremlin scripts might go away in a future version. I would consider them a legacy way of sending traversals to the server for execution. Bytecode is a nice way to serialize a traversal and it allows for Gremlin Language Variants (GLVs) in different programming languages that provide a really nice way to write Gremlin directly in the language of your choice, not only Java/Groovy, but also C#, Python or JavaScript
optimization ways: – enable batch loading – disable consistency checks – disable external and internal vertex checking – commit your transactions per every 10-20k created vertices – try ScyllaDB – increase id allocation to 1 million – use parallel threads with parallel transactions
Can only be provided through a local configuration file
storage.batch-loading
false
Enabling batch loading disables JanusGraph internal consistency checks in a number of places. Most importantly, it disables locking
GLOBAL_OFFLINE
Can only be changed for the entire database cluster at once when all instances are shut down
ids.block-size
10000
Set ids.block-size to the number of vertices, you expect to add per JanusGraph instance per hour.
MASKABLE
global but can be overwritten by a local configuration file
storage.buffer-size
1024
JanusGraph buffers write and execute them in small batches to reduce the number of requests against the storage backend. This setting controls the size of these batches.
Notes on batch loading:
For an embedded connection (JanusFactory): JanusGraphTransaction tx = graph.buildTransaction().enableBatchLoading().start();
For Remote connection: We need to set storage.batch-loading=true in “janusgraph-cql-es-server.properties” files; which is used to start the Gremlin-Server. Any change requires a restart of JanusGraph instance to take effect
Batch loading disables all data integrity checks if defined in a schema
Commit a transaction at the end.97 secondsA transaction is not supported.
More than 5 mins ( had to stop the test )3. Batch loading enabled with below additional setting; storage.batch-loading=true ids.block-size=1000000 storage.buffer-size=4096
Commit transaction after every 10K records77 secondsA transaction is not supported.
More than 5 mins ( had to stop the test )4. Without enabling batch loading;
Load 20K nodes with a rate of 2K requests per second70 seconds 300 seconds5. Batch loading enabled with below additional setting; storage.batch-loading=true ids.block-size=1000000 storage.buffer-size=4096
Load 20K nodes with a rate of 2K requests per second 63 seconds284 seconds Observation: – An embedded connection is way faster than Remote.
After inserting 1 million nodes; count query with timeout gremlin> g.V().count(); Evaluation exceeded the configured ‘evaluationTimeout’ threshold of 30000 ms or evaluation was otherwise cancelled directly for request [g.V().count();] – try increasing the timeout with the :remote command Type ‘:help’ or ‘:h’ for help. Display stack trace? [yN]
Composite indexes are very fast and efficient but limited to equality
Mixed indexes provide more flexibility than composite indexes and support additional condition predicates beyond equality. Mixed indexes are slower for most equality queries than composite indexes
The definition refers to the indexing backend name “search” so that JanusGraph knows which configured indexing backend it should use for this particular index. The “search” parameter specified in the buildMixedIndex call must match the second clause in the JanusGraph configuration definition like this: “index.search.backend”
In the code we need to set below;
mixedIndexConfigName = “search”; // this shuld be same as second clause in JG Config eg. “index.search.backend”
An unwanted program which poses a security risk to the user’s information or the system.
Malware Categories:
Trojans:
Trojans do not replicate. They install on the victim’s machine and perform malicious activities like keylogging, stealing sensitive information.
The Trojan which connects to remote IP and downloads other malware are further classified as Downloader and Trojans which carries at least one program, which it installs and launches are further classified as Dropper.
Rogue:
Uses misleading message or outright fraud to make the users purchase security software, which does not perform as they claim.
Worm:
This uses a computer or network resources to copy itself and spread to other victims. This may also include a code of other malware to damage both the system and the network.
The Worms can be further classified as:
Network Worm replicates through a network or internet
Email-Worm replicates through emails as file attachments
USB Worm replicates through USB devices
Peer to Peer Worm replicates through files sent over peer to peer
IM worm over instant messaging
IRC worm through Internet Relay Chat (IRC) channels
Bluetooth worm via Bluetooth broadcasting
Backdoor:
Creates a loophole in a host or in the network and allows the remote attacker to control it.
Rootkit:
Attacks the kernel module of the system and can be used by remote users to manipulate the device. This malware hides from the device’s security programs.
File Infector/Virus:
Integrates its own code to the data and program files in the user’s machine and thus making them as file infectors again.
Exploits:
Takes advantage of the vulnerabilities in a program or in the operating system to gain access or perform actions beyond what is normally permitted.
Potentially Unwanted Application:
Potentially Unwanted Applications (PUA) are not actually malware, but they create annoying changes in the user’s computer. They display ads on the browsers, install toolbars on the browsers, change the browser’s homepage and sometimes even installs other applications which display ads without the user’s knowledge.
Please refer the following link for more and detailed malware classification.
Portable Executable (PE) is the format used in Windows before which COFF (Common Object File Format) was used until the release of Windows NT.
PE is the format of executable object code in the Windows operating system. The common file extension which are based on the PE format are .exe, .dll, .cpl, .sys, .ocx, .scr, .mui, .efi etc.,
The PE format has a structure on the disk and on the memory upon which all the PE files execute.
The below links refers to the structure of the PE files.
After being infected by malware, as Incident Responder or forensic analyst how to find the root cause of attack.so here we will discuss the steps of malware analysis.
Fully Automated Analysis:
The easiest way to assess the nature of a suspicious file is to scan it using fully automated tools, some of which are available as commercial products and some as free ones. These utilities are designed to quickly assess what the specimen might do if it ran on a system. They typically produce reports with details such as the registry keys used by the malicious program, its mutex values, file activity, network traffic, etc.but we can’t know the internal behaviors of malware. Some of tools are Cooko, XecScan
Static Properties Analysis:
An analyst interested in taking a closer look at the suspicious file might proceed by examining its static properties. Such details can be obtained relatively quickly, because they don’t involve running the potentially malicious program. Static properties include the strings embedded into the file, header details, hashes, embedded resources, packer signatures, metadata such as the creation date, etc.
Manual Code Reversing/Dynamic Analysis:
Reverse engineering the code that comprises the specimen can add valuable insights to the findings available after completing interactive behavior analysis.
Manual code reversing involves the use of a disassembler and a debugger, which could be aided by a decompiler and a variety of plugins and specialized tools that automate some aspects of these efforts. Memory forensics can assist at this stage of the pyramid as well.
it provides the below benefits
Decoding encrypted data stored or transferred by the sample;
Determining the logic of the malicious program’s domain generation algorithm;
Understanding other capabilities of the sample that didn’t exhibit themselves during behavior analysis.
Behavioral Analysis:
Behavioral analysis involves examining how sample runs in the lab to understand its registry, file system, process, and network activities. Understanding how the program uses memory (e.g., performing memory forensics) can bring additional insights. This malware analysis stage is especially fruitful when the researcher interacts with the malicious program, rather than passively observing the specimen.
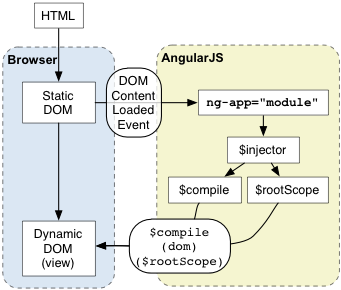
Finally, I got hands on AngularJS, let me summarize, it is easy to learn Angular, when you understand its jargon first . Dan Wahlin has done an awesome job putting it all together nicely to cover the part in 60ish minutes. Thanks Dan!!
Now, if you are one of those who have heard of this many times & willing to learn it, spend next few mins reading this further or take a look at this video, https://www.youtube.com/watch?v=i9MHigUZKEM ( Expected: Traditional Web Developer user)
Note : Angular 2 syntactically different from Angular 1.
What is AngularJS?
AngularJS is a very powerful JavaScript library. It is used in Single Page Application (SPA) projects with CRUD. It extends HTML DOM with additional attributes and makes it more responsive to user actions.
Why Angular? (you may want to skip the link)
This guy has explained it well..!! http://www.sitepoint.com/10-reasons-use-angularjs/ This star is the key, most people including me had a hard time to understand AngularJS in one go is because for these jargon, it makes AngularJS from other world.
Therefore I suggest to understand these terms first, it covers the half.
===================================================================
Data Binding : AngularJS provides 2-way data binding means, changes from model are directly reflected in view & vice-versa.
Directives : apply special behavior to attributes or elements in the HTML.
Expressions : a template is a JavaScript-like code snippet that allows Angular to read and write variables.
Scope : Scope is an object that refers to the application model. It is an execution context for expressions. Scopes are arranged in hierarchical structure which mimic the DOM structure of the application.
Controller is defined by a JavaScript constructor function that is used to augment theAngular Scope. Use controllers to:
Set up the initial state of the $scope object.
Add behavior to the $scope object.
Dependency Injection (DI) is a software design pattern that deals with how components get hold of their dependencies.
Services are substitutable objects that are wired together using dependency injection (DI). Use services to organize and share code across your app.
Angular services are:
Lazily instantiated – Angular only instantiates a service when an application component depends on it.
Singletons – Each component dependent on a service gets a reference to the single instance generated by the service factory.
Filters format the value of an expression for display to the user.
Module is a container for the different parts of your app – controllers, services, filters, directives, etc.
Providers, Services, Factory:
The injector creates two types of objects, services and specialized objects.Services are objects whose API is defined by the developer writing the service.Specialized objects conform to a specific Angular framework API. These objects are one of controllers, directives, filters or animations.
The injector uses recipes to create two types of objects: services and special purpose objects
There are five recipe types that define how to create objects: Value, Factory, Service, Provider and Constant.
Factory and Service are the most commonly used recipes. The only difference between them is that the Service recipe works better for objects of a custom type, while the Factory can produce JavaScript primitives and functions.
The Provider recipe is the core recipe type and all the other ones are just syntactic sugar on it.
Provider is the most complex recipe type. You don’t need it unless you are building a reusable piece of code that needs global configuration.
All special purpose objects except for the Controller are defined via Factory recipes.
Decorators are functions that allow a service, directive or filter to be modified prior to its usage.
JavaScript (“JS” for short) is a full-fledged dynamic programming language that, when applied to an HTML document, can provide dynamic interactivity on websites.
A JavaScript engine is a program or library which executes JavaScript code. A JavaScript engine may be a traditional interpreter, or it may utilize just-in-time compilation to bytecode in some manner.
Famous Four browsers & their respective Javascript Engines:
1. Google Chrome – V8
2. Mozilla Firefox – SpiderMonkey
3. Internet Explorer – Chakra
4. Safari – Nitro
The important thing here is a just-in-time compilation, which also answers concepts like, Variable Hoisting, Closures, Scope.
Javascript execution is a 2-pass process,
1. Compilation: all the declarations & heap memory allocations happens in this phase
A Global memory scope starts here & also creates the local scope memory for the function definitions
2. Execution: assignment & actual processing happens in here.
For every function execution, it again runs 2-pass process.
Compilation process starts the function & creates a reference pointer back to the Global scope.
Most of us think, “var e;” line no 17 would never be executed because of “return g()” but that’s the wrong assumption, JS compile phase understands only declarations so it creates a memory for “e”, this is called “Variable Hoisting“.
Similarly, for function g(), it creates its local scope in compilation phase & has a separate space for its own “var e = 0;” it helps us understand the local/global scope
Anything beyond the reach of a compiler is Garbage Collected in Javascript.
After execution of function “f(1); ” line 20, there is no way to reach function g, therefore its scope & memory would be cleaned also, it finishes f’s execution so, its scope is also deleted.
But let’s modify the code a little; to understand this in more detail;
Added,
var myG = f(1);
myG();
Here, a pointer to function “g” is created in the root scope.
Note lamda ‘g’ is not garbage collected.
This is basically a closure; it an implicit, permanent link between a function & its scope chain.
It prevents garbage collection also, used & copied as the “outer environment reference” anytime a function runs.
Special Thanks to Arindam Paul for his video: https://www.youtube.com/watch?v=QyUFheng6J0
Def: A closure is a function having access to the parent scope, even after the parent function has closed.
I know, its confusing to understand JS closures; I will try to explain below in as simple terms as I can;
Remember:
Aim of “closures” is to create access to ‘private’ variables of a function, even after that function is closed.
Immediately Invoking function only runs once.
Steps to create closure: (Counter Function)
Write a increment function which returns count = count +1; function(){ return count = count +1; }
Write an anonymous function which returns above function; also initialize counter here; function (){var counter = 0;return function(){return count = count +1;}}
Create an immediately invoking functiona. start with ()();
b. Put above function into first braces;
Assign this immediately invoking function to a variable & Done.>!!! Here, the final code would look like; var add = (function () {var counter = 0;return function () {return counter += 1;}})();add();
add();
Result : 2
Let’s understand it now;
As stated above, IIF only runs once; therefore counter gets initialized once; no matter how many times you call the function. Here the variable is ‘private‘, means it can only be changed by methods within that function.
For the inner function; that variable is accessible & in the return statement its value gets incremented by 1, every time it gets called. Here, the variable becomes ‘protected’ & not accessible for outside world.Wonderful..!! isn’t it?
Lets understand it with an analogy of planting a tree.
Step 1 : Plant a seed i.e called Seed Capital, it raises substantial funds to support the initial market research and development work for the company.
Step 2 : Initial care of the plant i.e Optimize : Series A, thisfunding is useful in optimizing product and user base.
Step 3: Growth i.e B Is For Build: Series B, taking businesses to the next level, past the development stage. Investors help startups get there by expanding market reach.
Step 4: Tree Scales : Series C, investors inject capital into the meat of successful businesses, in efforts to receive more than double that amount back.
Conclusion:
The rounds of funding work in essentially the same basic manner of planting a tree with expectations of its Fruits; investors offer cash in return for an equity stake in the business. Between the rounds, investors make slightly different demands on the start-up. Company profiles differ with each case study but generally possess different risk profiles and maturity levels at each funding stage.
The first web page was created by Tim-Berners Lee, a British scientist at CERN, the European Organization for Nuclear Research, located on the French-Swiss border near Geneva. The page went live at CERN on Dec. 20, 1990, and was opened up to the high-energy physics community on Jan. 10, 1991.
But it wasn’t until August of that year that Berners-Lee made the project public by posting a summary of it on several online forums, lastly on Aug. 22.
Some time later, Aug. 23, 1991 was named “Internaut Day,” which is now celebrated annually to recognize the launch of the World Wide Web. Although Berners-Lee is not sure why that date was chosen.
Internaut is a portmanteau of the words Internet and astronaut and refers to a designer, operator, or technically capable user of the Internet.
Internet + Astronaut = Internaut
Glossary : A portmanteau is a linguistic blend of words, in which parts of multiple words, or their phones (sounds), and their meanings are combined into a new word.
Finally, we bought an electronic water purifier at home, it was been a pain to arrange drinking water daily, so I did some market search about the available Water Purifier products, there are few companies in the market who provide many different products as per the type of water source, the first question by salesman, Corporation Water or Bore well Water? then he suggests UV or RO or both + MF +UF + TDS Controller + Automatic + what not…. never ending list. It is indeed a valid question; price of the product vary marginally as per the type. Concluding on the best fit to needs & budget we bought a RO+UV purifier, it does the job well & all are happy with the product. Mom & Nikita are happiest because, it has reduced their major household workload.
But, the most important thing I noticed was the way the product works, (amounts of rejected water)
*Image Credits to respective Companies.
Let me get to the point now, so called “Dirty water” is thrice of the purified water. In general conditions, it wastes 15 litres to purify 5 Litres.
Drinking Water (Food) is one of the three basic needs of humans. (Shelter, Cloths being other two)
According to WHO, the palatability of water with a total dissolved solids (TDS) level of less than about 600 mg/l is generally considered to be good; drinking-water becomes significantly and increasingly unpalatable at TDS levels greater than about 1000 mg/l.
I went through their user manual where they have mentioned below; (I doubt, how many of us read user manual?)
Recommended Uses of Rejected Water:
Although the rejected water has high concentration of salts. This rejected water usually goes down the drain but if required, can be used for gardening purposes. It has high concentration of salts and minerals which accelerate plant growth. Rejected water can also be used for cleaning purposes, i.e. utensils cleaning, mopping, etc.
In summers, every year India faces major droughts across the country, people die for water; forget purified water, in the rural area. Also they travel miles to get few litres. In contrast in cities, people drain water because it is rejected by their “purifiers”; it goes straight into sewage water drainage.
City Corporation supply drinking water, there are huge number of people, who uses this water directly for drinking, cooking & for all other needs. So when RO rejects the water it is still gone through, Sediment Filter & Activated Carbon Filter, which means it, is cleaner than at source and the next stop for such water is sewage drainage.
See the contrast here; most of you have connected water purifier to supply from overhead tank. The same overhead tank is used as a source for all the connections like bathrooms, toilets & the wash basin, where you brush your teeth, wash your face with the same water from overhead tank. Now, compare which water is cleaner? The one from direct tap or the rejected water from your purifier.
I know the fact it is hard water but still it can be used for utensils cleaning, in bathrooms and toilets.
But, people are very careless about precious Water, just because it is made easily available. Some educated fools lacks the sense of efforts goes in to make it reach you by the turn of a tap & talks about “Save Water Campaign” in the air conditioned hall with a mineral water glass to drink.
Let’s do some math now,
Eg. Suppose, 10 Lac people/families (Assume, 1 Family = 4 Persons) have installed water purifier at home & they use daily 15 litres of drinking water which roughly rejects 45-50 litres of water.
10,00,000 X 50 = 50,00,000 litres of rejected water goes into sewage daily, without use.
50,00,000 X 365 = 1,82,50,00,000 litres of water gets wasted per year.
Avg. 200 litres of water needed for a family per day.
1,82,50,00,000 / 200 = 91,25,000 families can use this water for a day.
Or one family can use this water for 25,000 years.
Please don’t discard “rejected water” by your purifier, SAVE WATER..!! SAVE LIFE..!! 🙂
===============================================================================
Pointing out the issue is easy, isn’t it? Let’s discuss the solutions.
Recycle, send this water back to Lower Water tank.
– Proactively, product companies should provide extra pipe to take the rejected water to storage tank.
– People who install the purifier can also afford the cost one more pipe.
Store the water near purifier for cleaning utensils.